The Transformer¶
A Basic Approach to the Encoder-Decoder Model¶
The seq2seq model sonsists of two subnetworks, the encoder and the decoder. The encoder, on the left hand, receives sequences from the source language as inputs and produces, as a result, a compact representation of the input sequence, trying to summarize or condense all of its information. Then that output becomes an input or initial state to the decoder, which can also received another external input.
At each time step, the decoder generates an element of its output sequence based on the input received and its current state, as well as updating its own state for the next time step.
The input and output sequences are of fixed size, but they don’t have to match.
The paper “Attention Is All You Need” introduces a novel architecture call Transformer. As the title indicates, it uses the attention mechanism. Like LSTM, Transformer is an architecture for transforming one sequence in to another one with the help of two parts (Encoder and Decoder), but it differs from the previously existing sequence-to-sequence models because it does not imply any Recurrent Networks (GRU, LSTM, etc.)
Recurrent Networks were, until now, one of the best ways to capture the timely dependencies in sequences. However, the team presenting the paper proved that an architecture with only attention-mechanisms without any RNN can improve on the results in translation task and other tasks. One improvement on natural Language tasks is presented by a team introducing BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
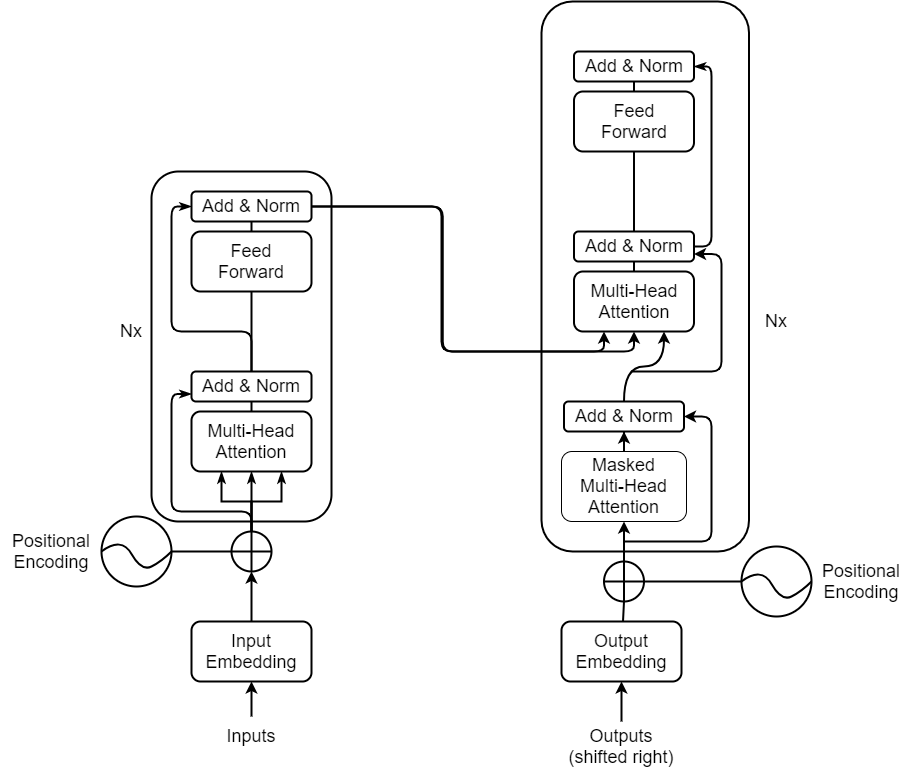
Fig. 7 Transformer Structure¶
Both Encoder and Decoder are composed of modules that can be stacked on top of multiple times, which is described by Nx in the figure. We see that the modules consist mainly of Multi-Head Attention and Feed Forward layers. The inputs and outputs (target sentences) are first embedded into an n-dimension space since we cannot use strings directly.
One slight bug important part of the model is the positional encoding of the different words. Since we have no recurrent networks that can remember how sequences are fed into a model, we need to somehow give every word/part in our sequence a relative position since a sequence depends on the order of its elements. These positions are added to the embedded representation (n-dimensional vector) of each word.
Q is a matrix that contains the query (vector representation of one word in the sequence), K are all keys (vector representations of all the words in the sequence) and V are the values, which are again the vector representations of all the words in the sequence. For the encoder and decoder, multi-head attention models, V consists of the same word sequence of Q. However, for the attention module that is taking into account the encoder and the decoder sequences, V is different from the sequence represented by Q.
To simplify this a little bit, we could say that the values in V are multiplied and summed with some attention-weight a.
This means that the weights are defined by how each word of the sequence (represented by Q) is influenced by all the other words in the sequence (represented by K). Additionally, the SoftMax function is applied to the wrights to have a distribution between 0 and 1. Those weights are then applied to all the words in the sequence that are introduced in V.
The Attention Mechanism¶
The previously described model based on RNNs has a severe problem when working with long sequences because the information of the first tokens is lost or diluted as more tokens are processed. The context vector has been given the responsibility of encoding all of the information in a given source sentence into a vector of few hundred elements. It made it challenging for the models to deal with long setences. Attention allows the model to focus on the relevant parts of the input sequence as needed, accessing all the past hidden states of the encoder, instead of just the last one. At each decoding step, the decoder gets to look at any particular state of the encoder and can selectively pick out specific elements from that sequence to produce the output.
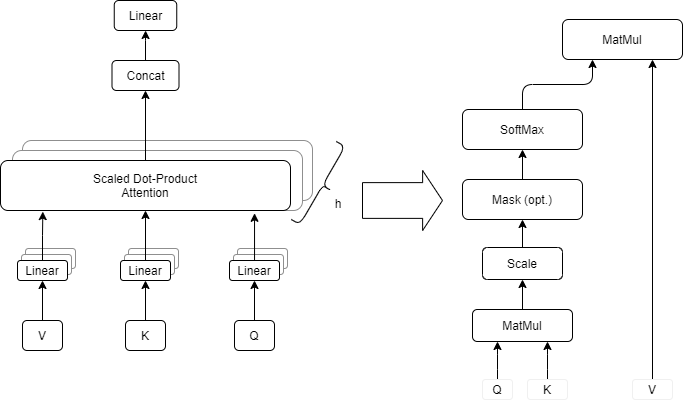
Fig. 8 Multi Head Attention¶
The alignment vector¶
The alignment vector is a vector with the same length as the input or source sequence and is computed at every time step of the decoder. There are three ways to calculate the alignment scores:
Dot product: We only need to take the hidden states of the encoder and multiply them by the hidden state of the decoder. General: Very similar to the dot product but a weight matrix is included. Concat: The decoder hidden state and encoder hidden states are added together first before being passed through a linear layer with a tanh activation function and, finally, being multiplied by a weight matrix.
The alignment scores are softmaxed so the weights will be between 0-1.
The context Vector¶
The context vector is the weighted average sum of the encoder’s output, the dot product of the alignment vector, and the encoder’s output.
Once our Attention class has been defined, we can create the decoder. The complete sequence of steps when calling the decoder are:
Generate the encoder hidden states as usual, one for every input tokens
Apply an RNN to produce a new hidden state, taking its previous hidden state and the target output from the previous time step
Calculate the alignment scores, as described previously
Calculate the context vctors
In the last operation, the context vector is concatenated with the decoder hidden state we generated previously. Then, it’s passed through a linear layer, which acts as a classifier for us to obtain the probobility scores of the next predicted word.
FFN